Requirement:
- Ubuntu installed and running
- Java Installed
Perform the following steps:
1) Add a Hadoop system user using below command
sudo addgroup hadoop_
sudo adduser --ingroup hadoop_ hduser_
Remember the password and enter your password, name and other details.
NOTE:
There is a possibility of below-mentioned error in this setup and installation process.
"hduser" is not in the sudoers file. This incident will be reported."
This error can be resolved.
For that login as a "root" user. So, execute the command
sudo adduser hduser_ sudo
Re-login as hduser_
2) Configure SSH
In order to manage nodes in a cluster, Hadoop requires SSH access
First, switch user, enter the following command
su - hduser_
This command will create a new key.
ssh-keygen -t rsa -P ""
Enable SSH access to local machine using this key.
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
Now test SSH setup by connecting to localhost as 'hduser' user.
ssh localhost
Note:
Please note, if you see below error in response to 'ssh localhost', then there is a possibility that SSH is not available on this system.
To resolve this -
Purge SSH using,
sudo apt-get purge openssh-server
It is good practice to purge before the start of installation.
Install SSH using the command-
sudo apt-get install openssh-server
3) Next step is to Download Hadoop
Select Stable
Once the download is complete, navigate to the directory containing the tar file
Enter , sudo tar xzf hadoop-2.2.0.tar.gz
Now, rename hadoop-2.2.0 as hadoop
sudo mv hadoop-2.2.0 hadoop
sudo chown -R hduser_:hadoop_ hadoop
4) Modify ~/.bashrc file
Add following lines to end of file ~/.bashrc
#Set HADOOP_HOME export HADOOP_HOME=<Installation Directory of Hadoop> #Set JAVA_HOME export JAVA_HOME=<Installation Directory of Java> # Add bin/ directory of Hadoop to PATH export PATH=$PATH:$HADOOP_HOME/bin
Now, source this environment configuration using below command
. ~/.bashrc
5) Configurations related to HDFS
Set JAVA_HOME inside file $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Change JAVA_HOME to /home/username/downloads/jdk1.8.0_05
There are two parameters in $HADOOP_HOME/etc/hadoop/core-site.xml which need to be set-
1. 'hadoop.tmp.dir' - Used to specify directory which will be used by Hadoop to store its data files.
2. 'fs.default.name' - This specifies the default file system.
To set these parameters, open core-site.xml
sudo gedit $HADOOP_HOME/etc/hadoop/core-site.xml
Copy below line in between tags <configuration></configuration>
<property> <name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value> <description>Parent directory for other temporary directories.</description> </property> <property> <name>fs.defaultFS </name> <value>hdfs://localhost:54310</value> <description>The name of the default file system. </description> </property>
Navigate to the directory $HADOOP_HOME/etc/Hadoop
Hadoop Setup Tutorial - Installation & Configuration
Now, create the directory mentioned in core-site.xml
sudo mkdir -p <Path of Directory used in above setting>
Grant permissions to the directory
sudo chown -R hduser_:Hadoop_ <Path of Directory created in above step>
sudo chmod 750 <Path of Directory created in above step>
6) Map Reduce Configuration
Before you begin with these configurations, lets set HADOOP_HOME path
sudo gedit /etc/profile.d/hadoop.sh
And Enter
export HADOOP_HOME=/home/guru99/Downloads/Hadoop
Next enter
sudo chmod +x /etc/profile.d/hadoop.sh
Exit the Terminal and restart again
Type echo $HADOOP_HOME. To verify the path
Now copy files
sudo cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml
Open the mapred-site.xml file
sudo gedit $HADOOP_HOME/etc/hadoop/mapred-site.xml
Add below lines of setting in between tags <configuration> and </configuration>
<property> <name>mapreduce.jobtracker.address</name> <value>localhost:54311</value> <description>MapReduce job tracker runs at this host and port. </description> </property>
Open $HADOOP_HOME/etc/hadoop/hdfs-site.xml as below,
sudo gedit $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Add below lines of setting between tags <configuration> and </configuration>
<property> <name>dfs.replication</name> <value>1</value> <description>Default block replication.</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hduser_/hdfs</value> </property>
Create directory specified in above setting-
sudo mkdir -p <Path of Directory used in above setting>
For eg: sudo mkdir -p /home/hduser_/hdfs
sudo chown -R hduser_:hadoop_ <Path of Directory created in above step> For eg: sudo chown -R hduser_:hadoop_ /home/hduser_/hdfs
sudo chmod 750 <Path of Directory created in above step>
For eg: sudo chmod 750 /home/hduser_/hdfs
7) Before we start Hadoop for the first time, format HDFS using below command
$HADOOP_HOME/bin/hdfs namenode -format
8) Start Hadoop single node cluster using below command
$HADOOP_HOME/sbin/start-dfs.sh
Enter "yes".
$HADOOP_HOME/sbin/start-yarn.sh
Using 'jps' tool/command, verify whether all the Hadoop related processes are running or not.
If Hadoop has started successfully then the output of jps should show NameNode, NodeManager, ResourceManager, SecondaryNameNode, DataNode.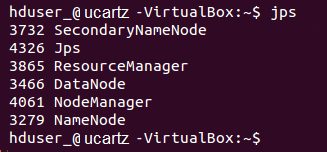
9) Stopping Hadoop
$HADOOP_HOME/sbin/stop-dfs.sh
Then enter
$HADOOP_HOME/sbin/stop-yarn.sh


























